Inteligência artificial é um tema que está em discussão constante no novo milênio. O uso de chatbots tem sido cada vez mais utilizado em diversos ambientes, seja para atendimento, monitoramento, suporte ou outras aplicações diversas. Designers de Interação e Programadores tem usado cada vez mais essas tecnologias para poder criar uma experiência melhor e mais dinâmica para o usuário.
Dentro da área da computação cognitiva, uma das empresas que está em muita evidência no mercado é a IBM, com sua tecnologia Watson.
A tecnologia Watson é uma amálgama de serviços de inteligência artificial que permite ao desenvolvedor criar plataformas de comunicação automatas com seus usuários. Para isso, a IBM disponibiliza diversas APIs de comunicação com determinados serviços. Para nosso exemplo de chatbot usaremos o serviço de Conversação do Watson.
Criar um chatbot com o Watson é bem mais simples do que parece. Porém, devemos deixar claro que a proposta deste tutorial é ser básico, ser um ambiente de entrada, simplificado porém funcional para o desenvolvedor ou designer interessado nesse tipo de tecnologia.
Atenção, você precisa de um servidor que possa ser autenticado na internet. Ou seja, não adianta testar de Xampp ou Wampp, você precisa testar ao menos de uma hospedagem compartilhada.
Preparando o Ambiente
Primeiramente você vai precisar de uma conta na Bluemix. A Bluemix é uma plataforma em nuvem de projetos da Big Blue (apelido dado a IBM pelo mercado). Para isso, basta entrar no site da empresa e clicar em Teste Gratuito 30 Dias.

Depois disso, siga as instruções para você preencher os seus dados básicos.
Após o preenchimento de seus dados, será pedido para você criar uma organização. Por algum motivo, você não verá a opção de América do Sul referente ao local, todavia você pode continuar selecionando SUL DOS EUA que não vai impedir o funcionamento do chatbot. Simplesmente siga as demais opções até chegar ao final.

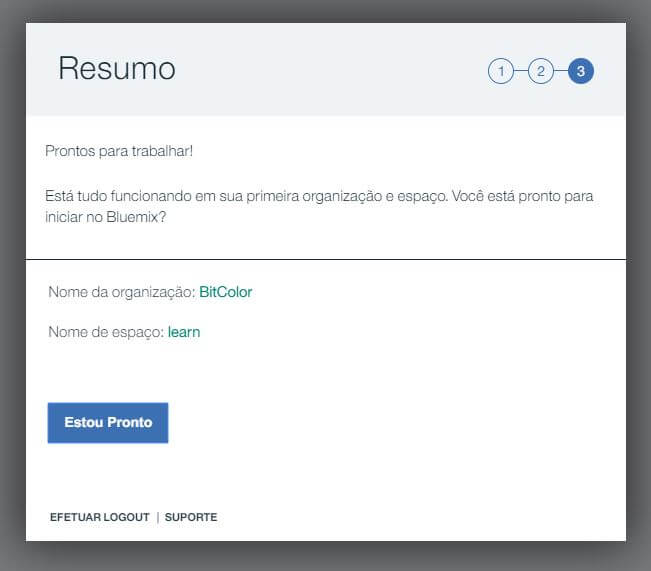
Assim que você finalizar, é possível ver uma área para criar Apps. Por hora você pode ignorar completamente isso. À primeira vista, o Bluemix parece ser um pouco difícil de navegar e encontrar algo por conta da diversidade de opções e APIs disponíveis.
No canto superior esquerdo você vai ver um menu hambúrguer. Clique nesse menu e selecione a opção Serviços. Lá, você vai ver a opção Watson.
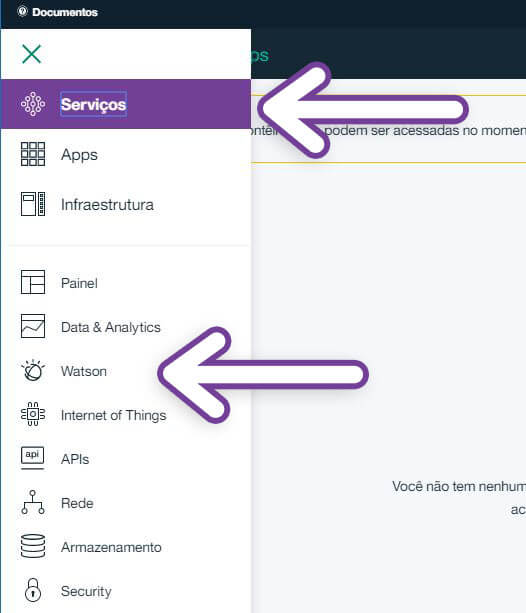
Como nosso tutorial é sobre chatbot, devemos criar um serviço do tipo Conversação. Clique no botão Criar serviço Watson e, na página que se abrirá, selecione a opção Conversation. A configuração do serviço é bem similar ao cadastro do próprio Bluemix.

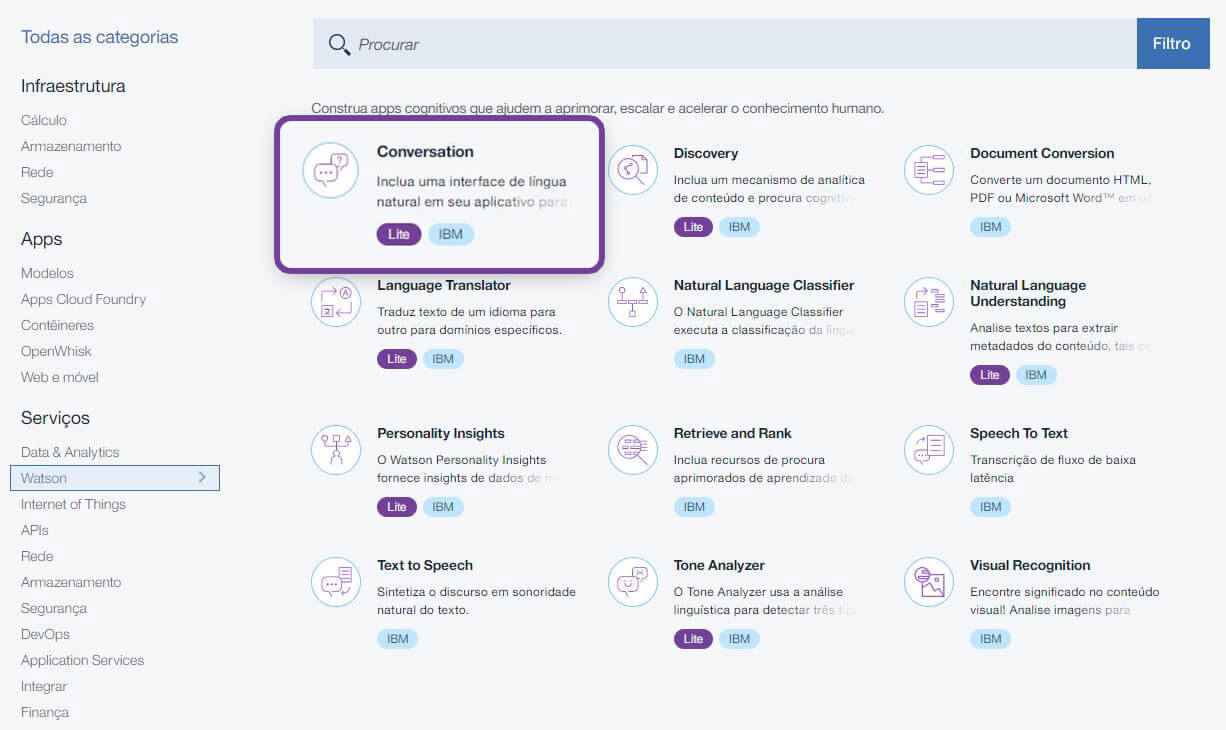
Esse serviço possui versões Lite (que é gratuita), Padrão e Premium (que precisa de consulta). Na versão Lite, que estamos usando para este tutorial, você possui até 10 mil requisições por mês e não poderá salvar os logs dos chats. Porém a versão padrão não é cara, cada requisição é uma fração inferior a metade de um centavo, o que é um valor aceitável para um sistema corporativo.

Agora é necessário “ensinar” ao Watson o que você quer que ele responda. Apesar dele já possuir uma inteligência base interna, que reconhece erros e contextos, você precisa treina-lo para que ele dê as respostas corretas para determinadas perguntas.
Para iniciar, você precisa criar um novo Workspace (por enquanto, pode ignorar o espaço de trabalho de exemplo).

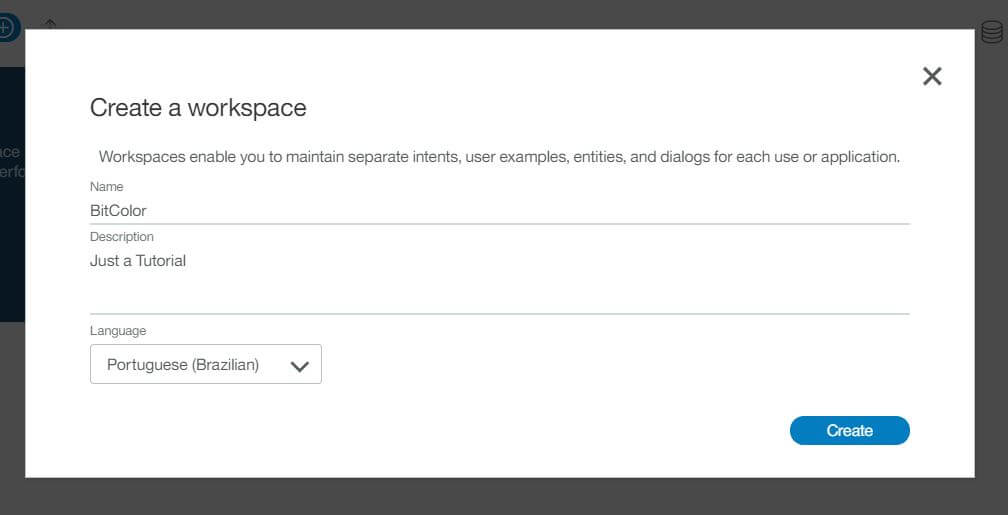
Atenção ao idioma do espaço de trabalho que você está criando.
Treinando o Watson
Uma vez criado o espaço de trabalho (Workspace), iniciaremos o processo de treinamento do Watson. Para isso, você deve primeiro criar um intent. Um intent é uma intenção de comunicação, ou seja, é um conjunto de interações padronizadas que o usuário poderá fazer com o chatbot.

Cada intenção que for criada precisa ter pelo menos 5 exemplos de interações para poder funcionar. A partir daí o Watson também irá entender perguntas similares. Não é necessário se preocupar com muitas variações. A tecnologia é inteligente o suficiente para trabalhar com diferenças básicas, erros de digitação e compreender contextos. Em nosso exemplo, vamos criar uma intenção com o nome de #Saudações e preencher com algumas interações básicas de saudações.

Uma vez criada as intenções desejadas (em nosso exemplo criamos apenas uma), você deverá criar as possíveis respostas para essas intenções e suas variações. Para isso, você deve ir na área de Dialog.
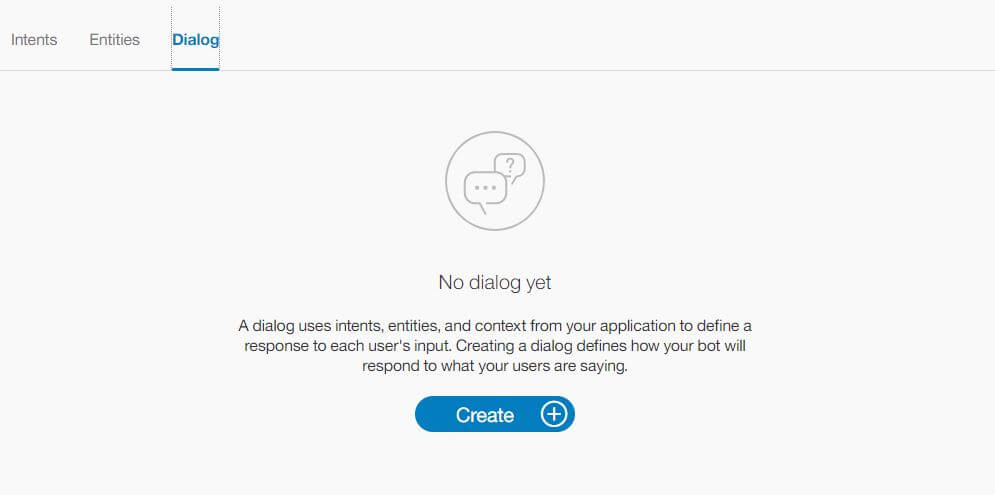
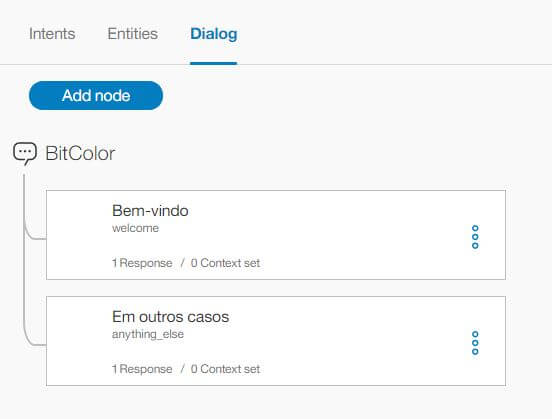
Um diálogo (Dialog), como o nome já diz, consiste em um conjunto de interações e condições dessas interações, com uma resposta, que pode ou não resultar em um feedback para encerrar um processo de comunicação.
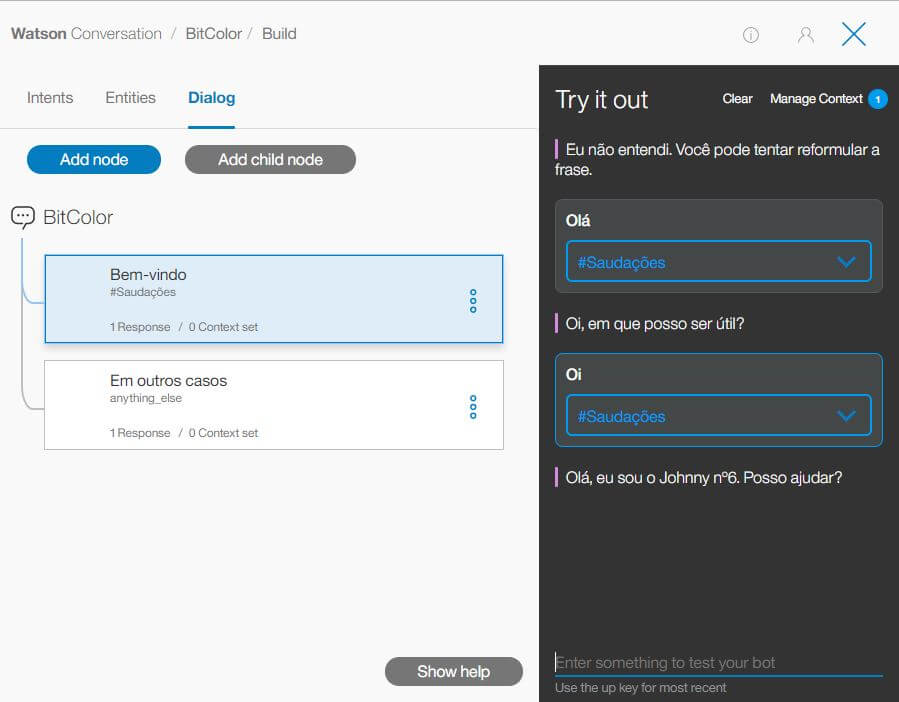
No Watson, o diálogo é organizado em um sistema de árvores, que possui uma lógica de nós e subnós. Para nosso exemplo, vamos criar um novo nó para responder a intenção de saudação que criamos anteriormente. Clique em Add node.
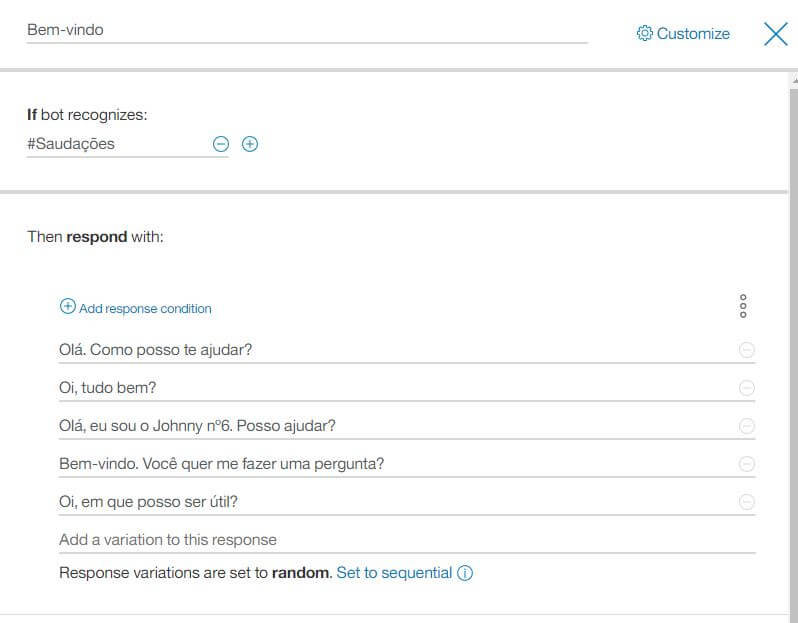
Após dar um nome ao nó, você deve colocar o que o bot irá reconhecer. A intenção é representada pelo símbolo de hash (#). Então, basicamente diz: Se o bot reconhecer a intenção #Saudação, então responda com:
Você pode colocar quantas respostas você quiser. Quanto mais respostas você colocar, maior a quantidade de diálogo possível, deixando o ambiente de comunicação mais natural e otimizando o aprendizado.
Como opções adicionais você pode colocar as respostas em forma sequencial ou aleatória. Ainda é possível criar condições específicas de contextos ou aguardar por respostas específicas à retóricas do chatbot.
Com tudo isso preenchido, você já pode testar o chatbot. O próprio ambiente do bluemix possui uma área para testes. Clique no ícone com o balãozinho no canto superior direito e experimente o diálogo que você acabou de criar.
Implementando o Back-end
A API do Bluemix funciona através de comunicação cURL Essa comunicação é feita a partir de envios de informações via método POST e mediante autorização de acesso. Por isso, vamos precisar de algumas informações básicas do serviço de comunicação que criamos.
Caso você queira ver outros exemplos que usam cURL, acesse nosso tutorial sobre preenchimento automático de formulário com o CNPJ ou o tutorial sobre preenchimento automático de endereço a partir do CEP.
Então, antes de criamos o código, você vai precisar das seguintes informações:
- Workspace ID
- Username
- Password
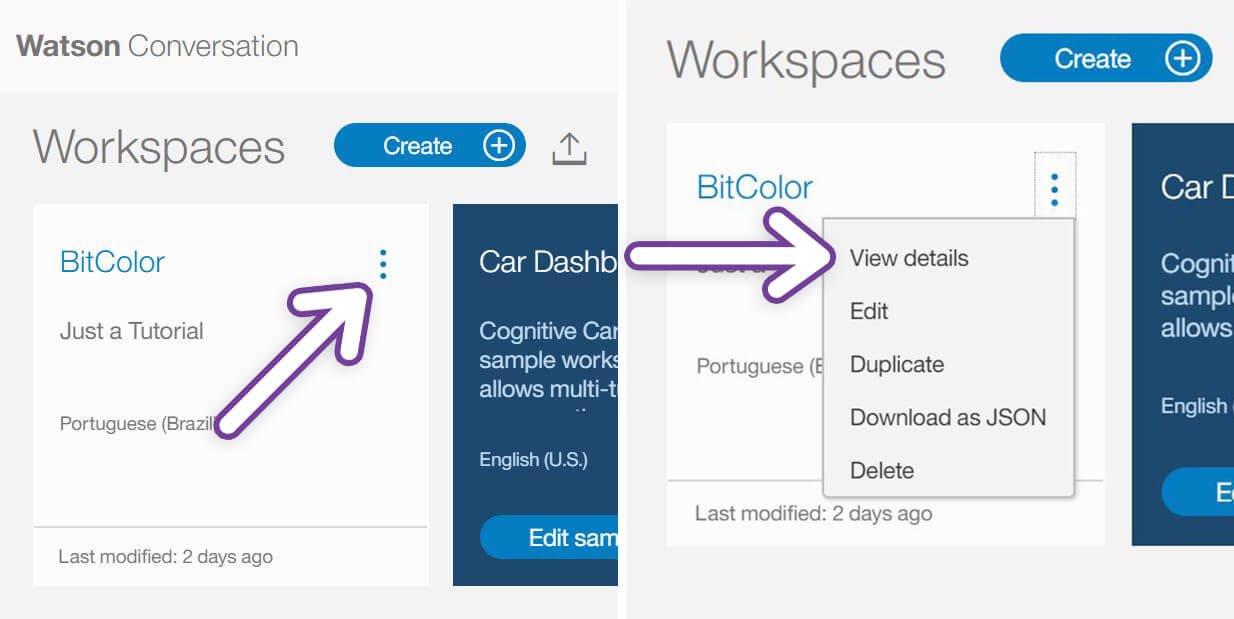
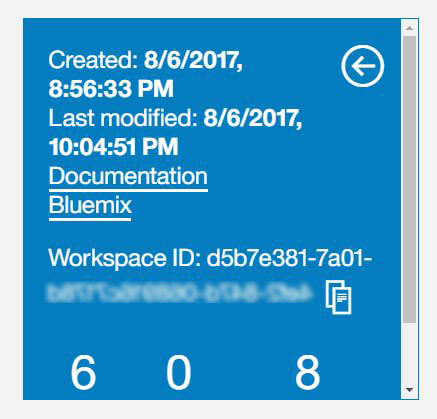
O Workspace ID pode ser adquirido lá naquela tela de criação/seleção de ambientes de trabalho (Workspaces). Basta clicar no botão de menu, no canto superior direito do cartão referente ao workspace que criamos, em seguida clicando em View Details.
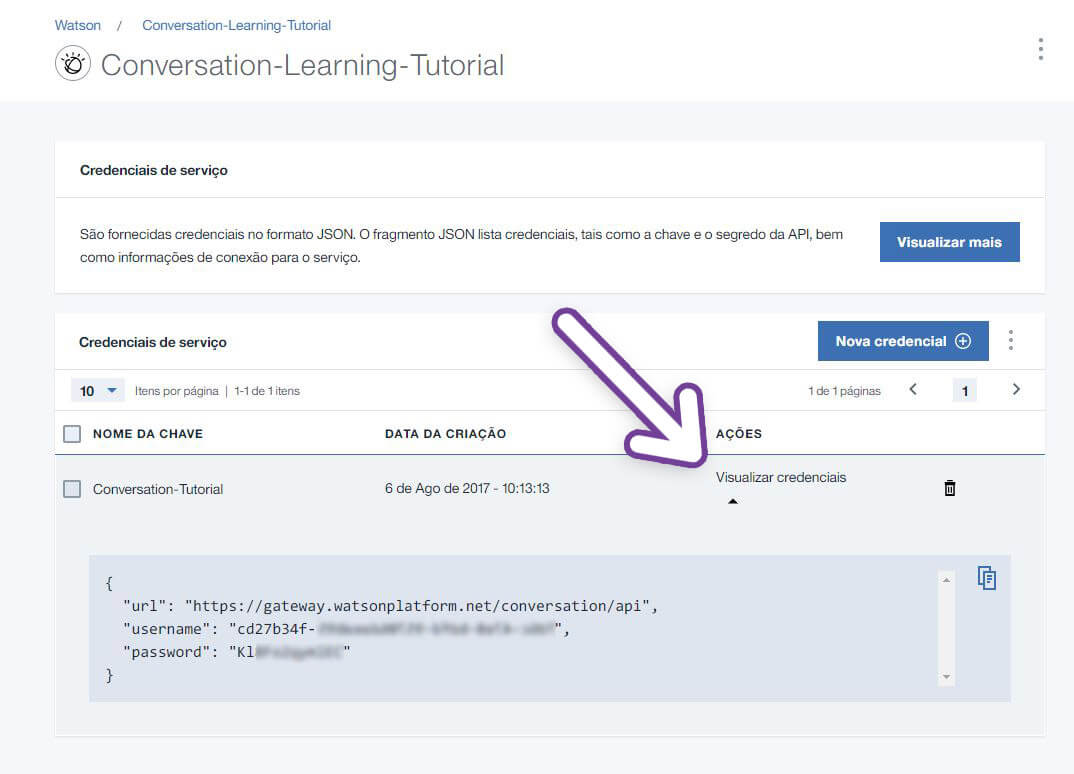
Para conseguir o login e senha do serviço de conversação, volte a tela onde você cria os serviços e vá na opção Credenciais de Serviço. Nessa área você pode visualizar ou criar novas credenciais, conseguindo assim o username e password que vamos precisar mais adiante.

ATENÇÃO
A IBM mudou a forma de autenticação. Agora, ao invés de você ter acesso ao username e password, as novas conexões usarão a autenticação AIM e não mais a autenticação por username password. Mais detalhes, veja a documentação: https://console.bluemix.net/apidocs/assistant.
Agora vamos ao código.
A API REST do Watson, como dito acima, funciona a partir de comunicação cURL e vai retornar um json completo com todas as informações para a comunicação. Para criarmos uma conversa simples, precisamos definir o código. Fique atento ao que precisa ser preenchido.
Exemplo usando PHP
conversa.php
Como o retorno é json, precisamos definir a página como text/plain, para evitar qualquer renderização incorreta.
header("Content-Type: text/plain");
Iremos definir então as informações que pegamos acima através das configurações do serviço de conversação. Lembre-se de substituir o código abaixo por seus dados.
$workspace = "d5b7e381-xxxx-xxxx-xxxx-xxxxxxxxxxxx"; $apikey = "xxxxxxxxxxxxxxxxx"; /*Antiga autenticação $username = "cd27b34f-xxxx-xxxx-xxxx-xxxxxxxxxxxx"; $password = "Klxxxxxxxx"; */
Precisamos agora capturar o texto que será enviado para o servidor do Watson. Para testes usaremos o $_REQUEST, do PHP. Por segurança, quando for trabalhar em modo de produção, troque para $_POST.
$texto = $_REQUEST["texto"];
Agora é necessário definir um identificador. Para manter o contexto de conversa, e o Watson saber que está conversando ainda com a mesma pessoa, é necessário passar um identificador. Esse identificador deverá ser único por conversa. Caso você esteja implementando em um sistema de gestão, por exemplo, você pode usar o nome de usuário, id, e-mail, ou algum outro tipo de identificação única.
No nosso teste criaremos uma hash única md5 e a armazenaremos em uma sessão. Dessa forma, garantimos a criação temporária de um identificador único funcional. Nosso bloco então ficará:
if (session_status() == PHP_SESSION_NONE) {
session_start();
}
if(isset($_SESSION["identificador"])){
$identificador = $_SESSION["identificador"];
}else{
$identificador = md5(uniqid(rand(), true));
$_SESSION["identificador"] = $identificador;
}
A URL da API REST deverá ser concatenada com o Workspace e o método que você está chamando. Dentro do gateway de conversação há vários métodos, desde status a tratamento de workspaces e diálogos. Através da documentação, você poderá explorar todos os métodos acessíveis para o Watson: https://www.ibm.com/watson/developercloud/conversation/api/v1/.
Em nosso exemplo básico, entretanto, iremos utilizar apenas o método message. É importante lembrar que é necessário adicionar a data da versão da API como parâmetro para que possa funcionar.
$url = "https://gateway.watsonplatform.net/conversation/api/v1/workspaces/" . $workspace; $urlMessage = $url . "/message?version=2017-05-26";
Para enviar os dados para o Watson, precisamos criar uma pequena string json. Como em nosso exemplo só precisamos enviar o texto e o identificador, podemos simplesmente concatenar o texto, deixando-o pronto para envio.
$dados = "{";
$dados .= "\"input\": ";
$dados .= "{\"text\": \"" . $texto . "\"},";
$dados .= "\"context\": {\"conversation_id\": \"" . $identificador . "\",";
$dados .= "\"system\": {\"dialog_stack\":[{\"dialog_node\":\"root\"}], \"dialog_turn_counter\": 1, \"dialog_request_counter\": 1}}";
$dados .= "}";
Como estamos tratando de json, devemos especificar o cabeçalho do tipo de dados que estamos enviando.
$headers = array('Content-Type:application/json');
Agora começa a comunicação. Para acessar a API, algumas exigências são feitas. É necessário ser enviado em método POST um json e ser uma comunicação segura, com identificação de usuário e senha. O bloco referente a comunicação ficará então:
$ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $urlMessage); curl_setopt($ch, CURLOPT_HTTPHEADER, $headers); curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_POSTFIELDS, $dados); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); //curl_setopt($ch, CURLOPT_USERPWD, "$username:$password"); Autenticação antiga curl_setopt($ch, CURLOPT_USERPWD, "apikey:$apikey") curl_setopt($ch, CURLOPT_HTTPAUTH, CURLAUTH_BASIC); $retorno = curl_exec($ch); curl_close($ch);
Por fim, para facilitar a leitura, vamos imprimir o json na tela com uma organização mais legível para um ser-humano.
$retorno = json_decode($retorno); echo json_encode($retorno, JSON_PRETTY_PRINT);
Com isso já poderemos ter uma resposta json, que, ao passar o texto, retornará algo similar como na imagem abaixo:

O código back-end completo fica (com comentários para ajudar a compreensão):
<?php
//Garantir que seja lido sem problemas
header("Content-Type: text/plain");
//Worskspace
$workspace = "d5b7e381-XXXX-XXXX-XXXX-XXXXXXXXXXXX";
/**
Antiga Autenticação
//Dados de Login
$username = "cd27b34f-XXXX-XXXX-XXXX-XXXXXXXXXXXX";
$password = "Kl8XXXXXXXXX";
**/
$apikey = "xxxxxxxxxxxxxxxxx";
//Capturar Texto
//Use $_POST em produção, por segurança
$texto = $_REQUEST["texto"];
//Verifica se existe identificador
//Caso não haja, crie um
if (session_status() == PHP_SESSION_NONE) {
session_start();
}
if(isset($_SESSION["identificador"])){
$identificador = $_SESSION["identificador"];
}else{
//Você pode usar qualquer identificador
//Você pode usar ID do usuário ou similar
$identificador = md5(uniqid(rand(), true));
$_SESSION["identificador"] = $identificador;
}
//URL da API
//(deve ser passado o método e a versão da API em GET)
$url = "https://gateway.watsonplatform.net/conversation/api/v1/workspaces/" . $workspace;
$urlMessage = $url . "/message?version=2017-05-26";
//Dados
$dados = "{";
$dados .= "\"input\": ";
$dados .= "{\"text\": \"" . $texto . "\"},";
$dados .= "\"context\": {\"conversation_id\": \"" . $identificador . "\",";
$dados .= "\"system\": {\"dialog_stack\":[{\"dialog_node\":\"root\"}], \"dialog_turn_counter\": 1, \"dialog_request_counter\": 1}}";
$dados .= "}";
//Cabeçalho que leva tipo de Dados
$headers = array('Content-Type:application/json');
//Iniciando Comunicação cURL
$ch = curl_init();
//Selecionando URL
curl_setopt($ch, CURLOPT_URL, $urlMessage);
//O cabeçalho é importante para definir tipo de arquivo enviado
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
//Habilitar método POST
curl_setopt($ch, CURLOPT_POST, 1);
//Enviar os dados
curl_setopt($ch, CURLOPT_POSTFIELDS, $dados);
//Capturar Retorno
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
//Autenticação
//curl_setopt($ch, CURLOPT_USERPWD, "$username:$password"); Autenticação antiga
curl_setopt($ch, CURLOPT_USERPWD, "apikey:$apikey")
curl_setopt($ch, CURLOPT_HTTPAUTH, CURLAUTH_BASIC);
//Executar
$retorno = curl_exec($ch);
//Fechar Conexão
curl_close($ch);
//Imprimir com leitura fácil para humanos
$retorno = json_decode($retorno);
echo json_encode($retorno, JSON_PRETTY_PRINT);
?>
Código do Front-End
Agora precisamos fazer a interação do usuário com o chatbot. Para isso, precisamos criar uma área do chat e o formulário que enviará os dados.
<div id="watson" class="watson"> <div class="mensagens"> <div class="area" id="chat"> </div> </div> <form id="mensagem" class="mensagem"> <input type="text" id="texto" name="texto" placeholder="Digite sua mensagem"/> <button type="submit">Enviar</button> </form> </div>
Com a área de chat criada, está na hora de adicionarmos os scripts necessários para fazer a comunicação com o back-end. Para facilitar, usaremos o método ajax do jQuery. Atenção aos comentários no código abaixo, pois eles explicam para quê serve cada linha.
<!--Importar jQuery. Retire caso sua página já faça a importação. -->
<script type="text/javascript" src="https://code.jquery.com/jquery-3.2.1.min.js"></script>
<script type="text/javascript">
//Submeter Formulário
$("#mensagem").submit(function(){
//Caso o usuário envie uma mensagem vazia
if($("#mensagem #texto").val() === ""){
//Adiciona na área de Chat a mensagem enviada pelo usuário
$("#chat").append("<div class=\"texto usuario\">...</div>");
//Faz um scroll para a mensagem mais recente, caso necessário
$(".mensagens").animate({scrollTop: $("#chat").height()});
setTimeout(function(){
//Adiciona uma resposta padrão afirmando que o usuário deixou o campo vazio
$("#chat").append("<div class=\"texto chatbot\">Você precisa digitar alguma coisa para prosseguir.</div>");
//Faz um scroll para a mensagem mais recente, caso necessário
$(".mensagens").animate({scrollTop: $("#chat").height()});
},1000);
return false;
}
//Inicia método AJAX
$.ajax({
//Substitua o caminho da URL pelo que você salvou o arquivo de backend
url: "/pasta/conversa.php?texto=" + $("#mensagem #texto").val(),
dataType: 'json', // Determina o tipo de retorno
beforeSend: function(){
//Adiciona a mensagem de usuário à lista de mensagens.
$("#chat").append("<div class=\"texto usuario\">" + $("#mensagem #texto").val() + "</div>");
},
success: function(resposta){
//Limpa o que o usuário digitou e foca no input para próxima interação.
$("#mensagem #texto").val("");
$("#mensagem #texto").focus();
//Caso haja um erro, o Watson retornará a mensagem de erro ao usuário
//Basta ler o objeto error para o usuário.
if(resposta.error){
$("#chat").append("<div class=\"texto chatbot\">" + resposta.error + "</div>");
return false;
}
//Colocar a resposta do Watson para o usuário ler
//A mensagem de texto pode ser lida a partir da lógica
//do json de exemplo da imagem no post
var mensagemChatbot = "<div class=\"texto chatbot\">";
mensagemChatbot += resposta.output.text[0];
mensagemChatbot += "</div>";
setTimeout(function(){
$("#chat").append(mensagemChatbot);
$(".mensagens").animate({scrollTop: $("#chat").height()});
},1000);
}
});
return false;
});
</script>
Observe que no código acima existe um método setTimeOut que ocorre sempre antes de adicionar a resposta do Watson. Isso é feito por uma decisão de experiência do usuário.
Uma resposta muito rápida pode causar uma confusão de interpretação e estranhamento.
Quando você está conversando com alguém, a tendência é, ao enviar uma mensagem, esperar que a pessoa ao menos pense na resposta e digite antes de responder. Um pequeno atraso de um segundo na resposta é um tempo mínimo esperado para dar uma maior naturalidade a conversa e ainda permitir que o usuário se prepare para receber uma mensagem. Essa é uma decisão puramente de UX. Caso queira, você pode retirar o setTimeout e irá funcionar normalmente, mas ao testar você poderá sentir que esse tempo de resposta faz falta.
Para finalizar, vamos colocar um estilo CSS para ficar mais agradável ao usuário.
<style>
.watson{
border: 1px solid #B0BEC5;
border-radius: 3px;
height: 50em;
max-height: 500px;
padding: 1em;
max-width: 500px;
margin: 0 auto;
display: flex;
flex-direction: column;
justify-content: space-between;
}
.watson .mensagens{
box-sizing: border-box;
overflow: hidden;
overflow-y: auto;
height: 100%;
}
.watson .mensagens .area{
display: flex;
justify-content: flex-end;
flex-direction: column;
min-height: 100%;
}
.watson .mensagens .texto{
border-radius: 2px;
box-sizing: border-box;
padding: .65em;
margin-top: .5em;
animation: popupmensagem linear .2s;
animation-iteration-count: 1;
-webkit-animation: popupmensagem linear .2s;
-webkit-animation-iteration-count: 1;
-moz-animation: popupmensagem linear .2s;
-moz-animation-iteration-count: 1;
-o-animation: popupmensagem linear .2s;
-o-animation-iteration-count: 1;
-ms-animation: popupmensagem linear .2s;
-ms-animation-iteration-count: 1;
}
.watson .mensagens .texto:first-child{
margin-top: 0;
}
.watson .mensagens .texto.usuario{
background-color: #ECEFF1;
color: #1A237E;
margin-right: 30%;
transform-origin: 0% 100%;
-webkit-transform-origin: 0% 100%;
-moz-transform-origin: 0% 100%;
-o-transform-origin: 0% 100%;
-ms-transform-origin: 0% 100%;
}
.watson .mensagens .texto.chatbot{
background-color: #FF5722;
color: white;
font-weight: bold;
margin-left: 30%;
transform-origin: 100% 100%;
-webkit-transform-origin: 100% 100%;
-moz-transform-origin: 100% 100%;
-o-transform-origin: 100% 100%;
-ms-transform-origin: 100% 100%;
}
.watson form.mensagem{
padding: 0;
margin-top: 1em;
}
.watson form.mensagem input{
border: 2px solid #476A7B;
border-radius: 3px;
padding: .5em .8em;
font-size: 16px;
display: block;
box-sizing: border-box;
width: 100%;
}
.watson form.mensagem input:focus{
border: 2px solid #1A237E;
outline: none;
}
.watson form.mensagem button{
background-color: #3F51B5;
border: none;
border-radius: 3px;
display: block;
padding: .5em 1em;
width: 100%;
font-size: 16px;
color: white;
margin-top: .5em;
}
/**Animação de Mensagem**/
@keyframes popupmensagem{
0% {
transform: scaleX(0.30) scaleY(0.30) ;
}
100% {
transform: scaleX(1.00) scaleY(1.00) ;
}
}
@-moz-keyframes popupmensagem{
0% {
-moz-transform: scaleX(0.30) scaleY(0.30) ;
}
100% {
-moz-transform: scaleX(1.00) scaleY(1.00) ;
}
}
@-webkit-keyframes popupmensagem {
0% {
-webkit-transform: scaleX(0.30) scaleY(0.30) ;
}
100% {
-webkit-transform: scaleX(1.00) scaleY(1.00) ;
}
}
@-o-keyframes popupmensagem {
0% {
-o-transform: scaleX(0.30) scaleY(0.30) ;
}
100% {
-o-transform: scaleX(1.00) scaleY(1.00) ;
}
}
@-ms-keyframes popupmensagem {
0% {
-ms-transform: scaleX(0.30) scaleY(0.30) ;
}
100% {
-ms-transform: scaleX(1.00) scaleY(1.00) ;
}
}
</style>
E agora? Funciona mesmo?
Veja o exemplo abaixo, utilizamos exatamente o mesmo código. Lembre-se que há apenas poucas interações e respostas criadas para este tutorial, então não espere ter uma conversa muito avançada com este chatbot.
Obs. Está sendo utilizada no exemplo uma conta Lite, então é possível que quando você testar já tenha acabado o limite mensal.
Caso você deseje um pouco mais de segurança, recomendamos que você utilize um arquivo .htdocs na pasta em que está o conversa.php, com o conteúdo abaixo. Evitando, assim, acesso externo.
#Evitar Acesso Externo Order Deny,Allow Deny from all Allow from 127. # localhost
Faça o Download do Código no Github, se preferir:
Download
Caso tenha apreciado este conteúdo, dê uma passada lá na página da VelhoBit no Facebook e deixe seu like. Compartilhe este post com colegas e interessados na área de tecnologia e não deixe de conferir o restante dos artigos no blog.
Até o próximo tutorial.